
Using Netscaler HTTP callouts for real-time GeoIP and anonymous proxy detection
Here’s the scenario: Contoso Inc (good name as any eh?) want to block users from a specific country from accessing their infrastructure. Because these users are particularly smart, they’ve been using anonymous proxies that use frequently changing IP addresses to circumvent regular GeoIP location detection, so the company, after learning the differences between nordvpn and expressvpn , decides to block all IPs from anonymous proxies and use a real-time service.
And conveniently they already have Netscaler technology in place to protect and accelerate their web sites. Good choice Contoso!
I’m actually going to detail two different ways of achieving this, one using a freely available (but only updated monthly) static GeoIP database, and the other using a realtime GeoIP service that meets the original requirement.
We’re going to use quite a few of the Netscaler features: GSLB database, load balancing, responder, http callouts, integrated cache and pattern sets, so make yourself a cuppa, grab a biscuit and let’s go!
As with all my blog posts, click on a screenshot to open a larger version.
Static Country database
Maxmind are one of the largest and most popular providers of GeoIP data, so we’re going to utilise their GeoLite service to obtain a free GeoIP database of countries and anonymous proxies. The static database blocking method is briefly documented here but I’m going to configure it step-by-step with screenshots.
Upload our GeoIP database
Download the “Geolite country” database zip and unzip the CSV file. Upload this using SFTP to your Netscaler appliance into the following folder: /var/netscaler/locdb
We now need to load the contents into the GSLB service running on the Netscaler. Ensure that GSLB is enabled as a feature, then navigate to GSLB -> Location and select the “static database” tab
Click on Add, change the location format to “geoip-country”
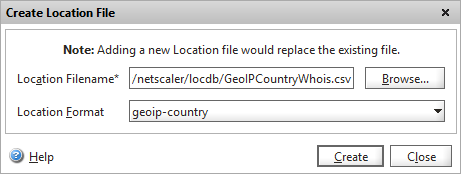
Adding a static GeoIP database file
and then browse to the location where you uploaded the CSV file and choose Select, then Create.
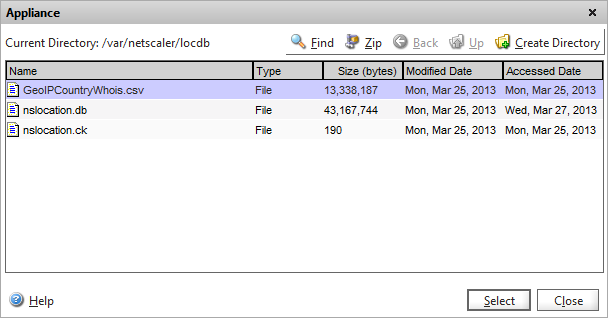
Browse to the location of the CSV file
If you’re a command-line junkie, the equivalent ns command is:
add locationFile "/var/netscaler/locdb/GeoIPCountryWhois.csv" -format geoip-country
If you want to check that the database loaded correctly, issue the following command from a ssh session, or the console:
show locationparameter
Which should give the following output:
> show locationparameter Static Proximity ---------------- Database mode: File Flushing: Idle; Loading: Idle Context: geographic Qualifier 1 label: CountryCode Qualifier 2 label: Country Qualifier 3 label: Region Qualifier 4 label: City Qualifier 5 label: ISP Qualifier 6 label: Organization Location file (format: geoip-country): /var/netscaler/locdb/GeoIPCountryWhois.csv Lines: 178306 Warnings: 0 Errors: 0 Current static entries: 178306 Current custom entries: 0 Done
Configure responder action
We now need to decide (well, the client does) on what should happen when a user from one of the “banned” regions or anonymous proxies hits the website. If you are blocking because of repeated malicious attacks, you’d probably just want to DROP the request without any response, but if you’d rather tell the user why they aren’t getting the webpage they expected, you can configure the Netscaler to respond with a HMTL page offering an explanation.
Ensure the Responder feature is enabled, and navigate to Responder -> Actions
Add a new action, and give it an appropriate name. For this example, I’m going to respond with a very basic HTML page with a simple message so I choose “Respond with” as the type, and enter my HTML inside quotes straight into the policy.
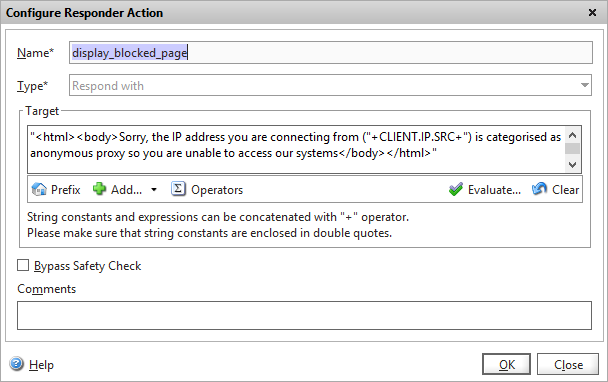
Configuring the responder action
If you implemented this on a production website you’ll soon have the corporate branding police after your blood, so you’d probably request a better-looking branded version from the web design department, and upload it using the “Respond with HTML page” option:
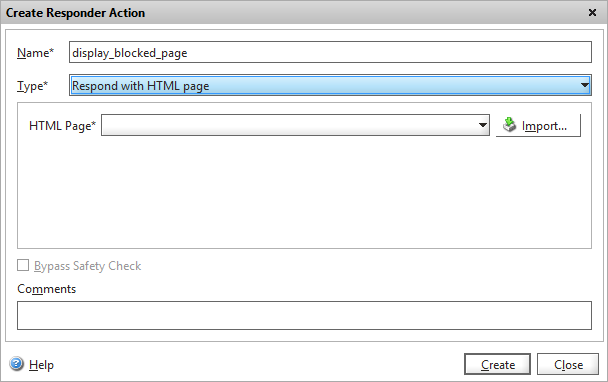
Respond with complete HTLM page
Configure responder policy
Now we’ve configure what needs to happen in the responder action, we need to configure the when i.e. the responder policy.
Add a new policy under Responder -> Policies.
Set the policy action to the action you created previously, and configure the expression to block IP’s from country “A1” which equates to anonymous proxies in our GeoIP database. You can of course substitute this for any valid country code from the GeoIP database.
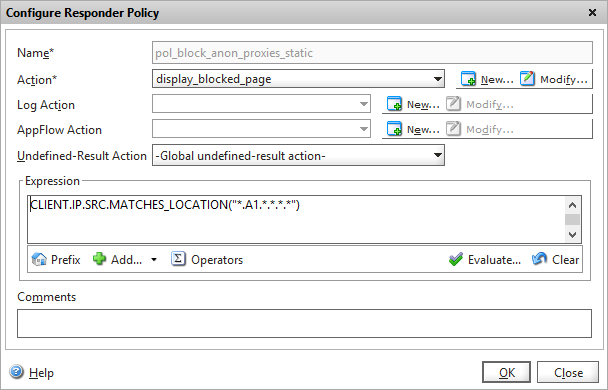
Add a responder policy that blocks country type “A1”
So far I’ve not really covered any exceptions to our blocking rule, such as search engines, but I’ll be covering them in the Realtime section later, and the same principles would apply when using this static database approach.
Bind responder policy
So, all that remains is to bind our new responder policy to the load-balanced virtual server that you want to protect using the policy manager and your protection is now in place.
Testing
But how do you know it’s working without calling up some unfriendly hacker in your blocked region and ask them to visit your website? Well, the hit counter on the policy will increment when it’s triggered, so if it remains at zero then you might have a problem.
One way I use to test my policies are working is to change the country to match my current location, but narrow the scope of the policy so that it only applies from my own PC to avoid creating a denial of service to everyone.
So in the above example, you might use the following expression in the responder policy:
CLIENT.IP.SRC.MATCHES_LOCATION("*.GB.*.*.*.*")&&CLIENT.IP.SRC.EQ(1.2.3.4)
This would trigger the block only if both policies matched: GeoIP detected my location as GB plus the IP address matched my internet IP address of 1.2.3.4. I can now visit the website, check that I receive the correct message, and that the policy hit counter is incremented. Remember to remove this test expression though once you’re happy!
Static protection of a website using free GeoIP data – done! Let’s delve a bit deeper into Netscaler functionality and use a realtime service.
Realtime web service
Maxmind also provide a realtime GeoIP database via a web service API. This has the advantage that you are more likely to catch anonymous proxies that change IP address to avoid detection which the static database misses. The disadvantage is that you have to pay, but hey, Contoso Inc has deep pockets and blocking these users is worth the additional cost.
Define Maxmind API service
First we need to define the Maxmind API service to our Netscaler by creating a server, service and load-balanced virtual server.
Create a new server – note we use the hostname, which will require our Netscaler to be able to resolve internet DNS (which it can). We can of course use an IP address, but it’s highly likely that Maxmind use their own load-balancing or GSLB service to provide their API, so the IP address could change at any time.
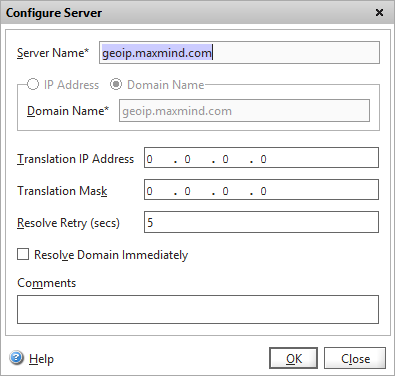
Add the Maxmind server
Create a HTTP service based on the server we’ve just added. I’ve used the default TCP monitor.
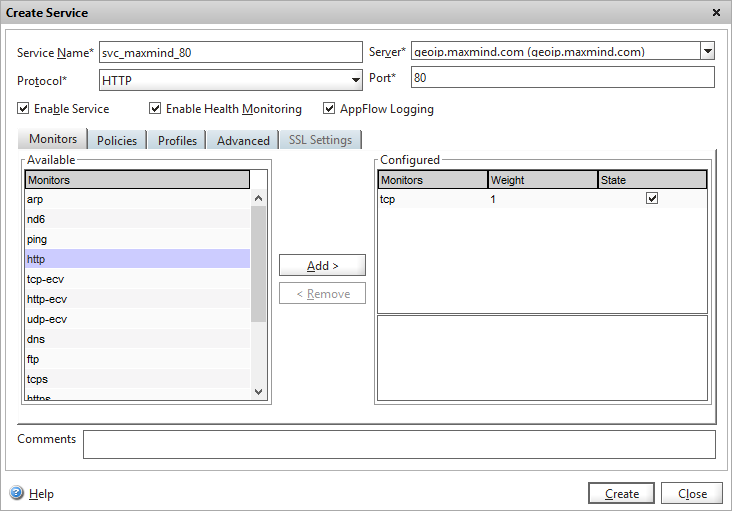
Add a HTTP service that uses the Maxmind server
And finally add a load-balanced virtual server that exposes the service to other Netscaler services. Note we’ve unticked the “Directly addressable” flag which means we don’t need to give it an IP address, and it won’t be exposed on any of our external VIPs – it’s for internal use only.
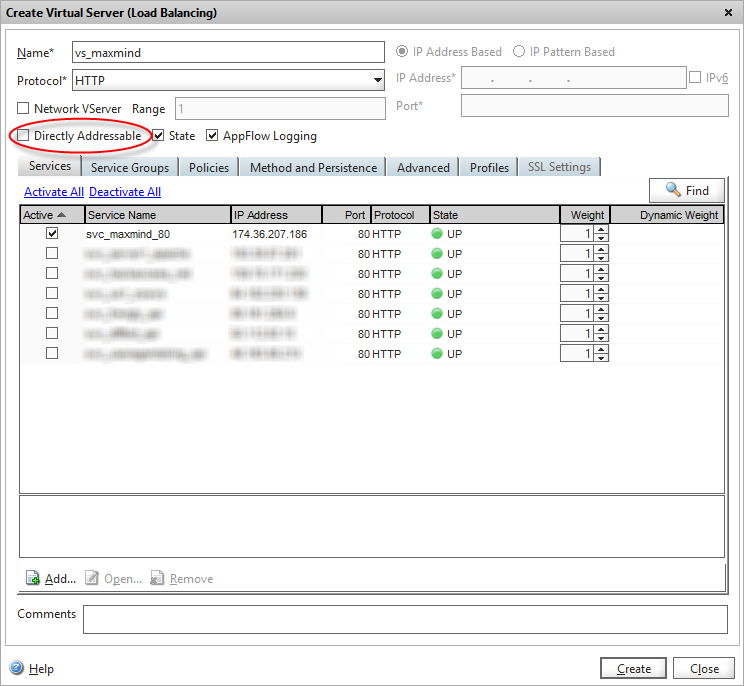
Add an internal HTTP load balanced VS for the Maxmind API service
Create a HTTP callout object
Navigate to AppExpert -> HTTP Callouts and click on Add. Give it a suitable name, and choose the load-balanced virtual server we’ve just created in the drop-down list. But wait – we can add the Maxmind API IP address right here! Why did we go to the trouble of creating a server, service and virtual server? Well, when we come to optimising our callout’s later on, we’re going to need to apply a policy to the Maxmind API load balanced virtual server, and if we bypass that by using the direct IP address, we’ll also bypass our policy engine.
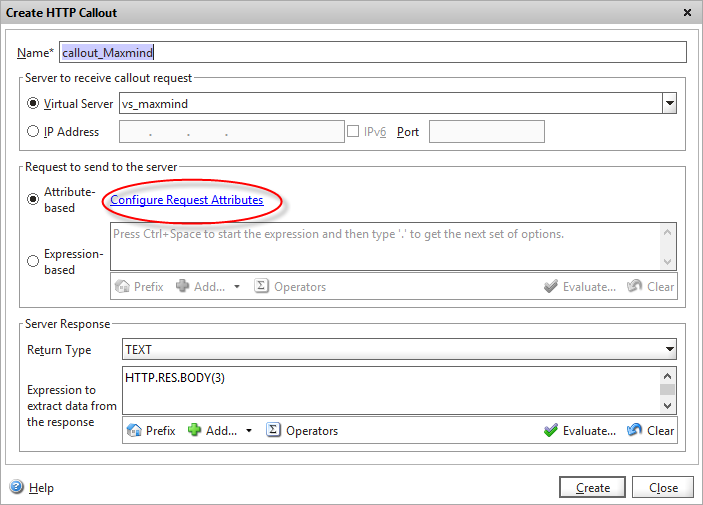
Add a new HTTP callout
I’ve also configured the return text to be TEXT (as it’s a country code that gets returned) but you can also choose numeric and boolean.
In the Server Response we can do some post-processing on the API response if we need to massage the data at all, however in this case the data is already in a format we can use so we’ll just return the first 3 bytes of the raw HTTP payload body, which we know contains our two-digit country code.
Build HTTP callout request
We now need to define the format of the HTTP request that we’ll be sending to the Maxmind API to ensure it matches the format specified in their API specification.
Click on the “Configure callout request attributes” highlighted and a new dialog opens
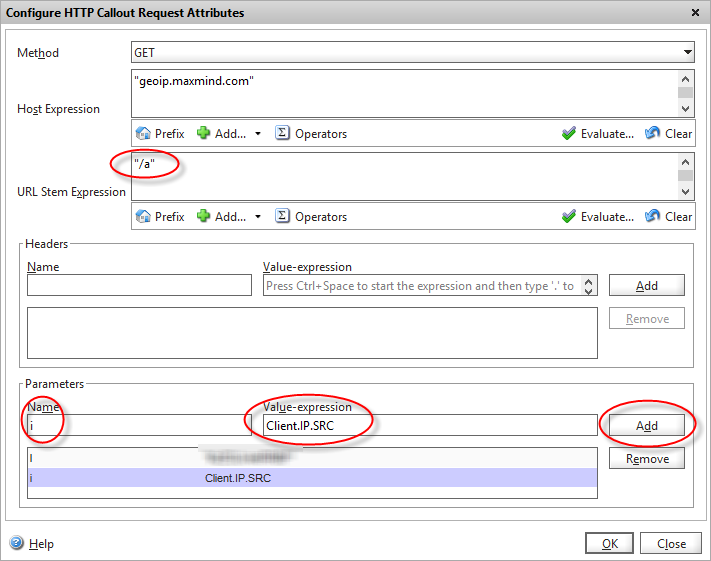
Configure the callout request that gets sent to the Maxmind API
This is where we build the HTTP request that will query the Maxmind API.
Firstly, we’ll set the Method to “GET” (Maxmind actually support GET and POST).
In the “Host Expression” we can customise the HTTP header that get’s sent if required, but in our case we’ll just pass the hostname of the API service we’re calling. Note we’ll be using this value later in another policy so take note of its contents. As it’s an an expression field, you have to enclose it in quotes as it’s a literal value.
The URL stem expression is where we define the query string that we need to call. From the API specs, Maxmind have several different stems based on which GeoIP database you are querying. For the country service, the stem is “/a”
The final task is to define the parameters that we will pass to the API. There are two parameter/value pairs that we need to add. “i” which is the IP address we want to look up, and our API license key “l” that identifies us to the Maxmind service.
As we want to query the IP address of the visitor who’s accessing our page, we use the expression CLIENT.IP.SRC in the “i” parameter.
OK these two dialogs, and we’ve now created the callout object.
Create the callout policy
We now need to define how we’re going to use our callout policy by modifying our responder policy we created for the static GeoIP lookup to utilise our HTTP callout instead.
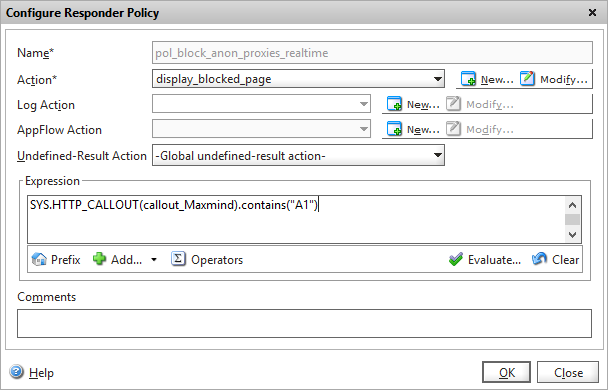
A responder callout policy that triggers our HTTP callout
As you can see, it’s quite simple to reference the callout value in Expressions, and you can use this in expressions applied to other services such as rewrite. And it’s really that simple….OK, not quite…there’s a bit more optimisation work we need to do.
Optimising our call-out
Before we unleash our HTTP call-out onto our production website by binding this policy to the load balanced virutal server that hosts our main site, we need to add some refinements that will avoid unnecessary calls to our GeoIP provider and cause our site to load slowly.
Ignore Search Engines
We may need to allow search engines to crawl our site from the blocked region, plus it’s worth avoiding using up our chargeable GeoIP API calls on automated robots and crawlers that we don’t care about.
To prevent call-outs being issued for search engines we will check the user-agent header of an incoming request, and only perform the GeoIP callout if it’s not a search engine that’s crawling the site.
The expression syntax for our policy would be something like
HTTP.REQ.HEADER("user-agent").SET_TEXT_MODE(IGNORECASE).CONTAINS("Googlebot").NOT
Breaking down the above, as it’s quite a complex compound expression, we’re extracting the “user-agent” header from the HTTP REQuest, telling the Netscaler to ignore the case, and checking if it contains the string “Googlebot”, and finally negating the result so the expression returns TRUE if the string is not present in the user agent (i.e. the person requesting our page isn’t the Googlebot). As soon as the expression processor encounters a FALSE when all expressions are ANDed, no further processing is performed, so if the requesting user-agent IS Googlebot, the expression returns FALSE because of the final .NOT and a call-out is avoided.
Now obviously Google isn’t the only search engine (much as they’d have you otherwise believe) so to avoid putting a long list of “OR” queries to check for other user-agents in the responder policy, we’ll define a pattern set of user-agents that we want to check for. Pattern sets are essentially lists of data, with optional indexes that can be referred to in string comparisons using the EQUALS_ANY or CONTAINS_ANY expressions.
Add the pattern set under AppExpert. I this example I’m adding three popular search engines, Google, Yahoo and MSN.
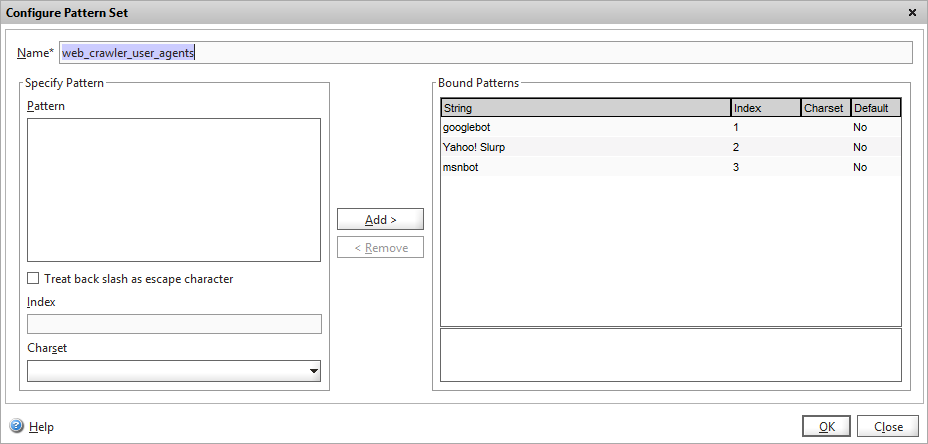
Adding a Pattern set of search engine user agents
To make up a more complete list you can find plenty of details of the popular search engine user-agent strings on the internet
Interestingly that site I’ve linked to provide a web service API to dynamically query if the user agent is a known search engine! Are you thinking what I’m thinking? No, and you’re right..you wouldn’t want to do this in a real environment as it’ll slow down your site too much (plus probably overload a very useful and free service) but for a bit of fun see the very end of this blog post for another example of using a http call-out to determine whether our visitor is a known search engine! HTTP call-out madness!
So with the Pattern set in place, our new responder policy expression now becomes:
HTTP.REQ.HEADER("user-agent").SET_TEXT_MODE(IGNORECASE).CONTAINS_ANY("web_crawler_user_agents").NOT
Don’t query on non-textual resonses
If you were utilising a callout inside a rewrite policy to insert or change data in transit, you’d want to optimise your callouts to only occur to textual pages that would require possible rewrites, so you wouldn’t issue callouts for any other content (e.g. images). To achieve this we add some addition logic to our policy expression:
HTTP.REQ.HEADER("user-agent").SET_TEXT_MODE(IGNORECASE).CONTAINS_ANY("web_crawler_user_agents").NOT && HTTP.RES.HEADER("Content-Type").EQ("text/html")
Note we’re extracting the user-agent string from the HTTP REQuest header, and the content-type from the RESponse header (as the content-type isn’t known until you actually have some content retrieved from the back end)
Caching the call-out response
Now, performing a HTTP call-out for a single response is fine if the response comes back negative and we drop the connection or display a blocked message. But if the request is coming from an allowed country, then we’ll soon be receiving dozens, possibly hundreds of further requests as the users browser builds the target web page by requesting all the components referred to in the HTML source (css files, Javascript, images etc)
As our HTTP call-out policy is bound to a responder policy, it get’s called on every HTTP request.
If left configured this way, this would both slow down the rendering of our site enormously, as every request would trigger a HTTP call-out to determine whether to allow the request or not. It would also use up our quota of API calls pretty quickly, as rendering a single web page for one visit can results in dozens or even hundreds of individual HTTP requests and responses.
If only there was some way of caching the results of our HTTP call-out, so that that API call is only made once for that IP address on the initial request, then all subsequent requests come from a fast in-memory cache. Aha! you cry…isn’t that what the Netscaler integrated cache is for? And you’d be right. Let’s put it to good use!
Enable and configure integrated caching
If you aren’t already using the integrated cache, you first need to enable the feature, and configure the memory usage (which defaults to zero, which means even enabled, the Netscaler won’t cache anything!). I’ve set the initial cache size here to be 512MB.
Note that if you are POSTing data to an API, you also need to increase the maximum POST body length from zero, which looks like it’s a bug
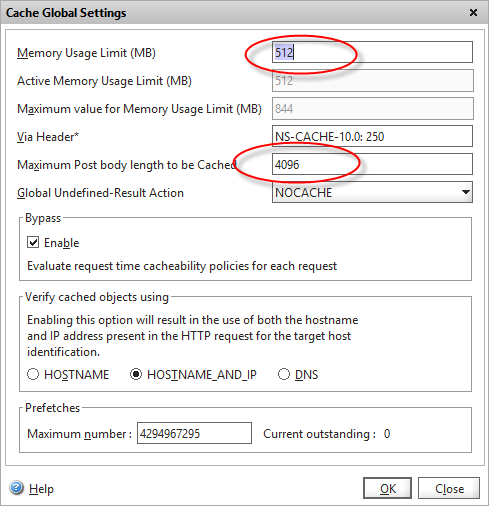
Configure cache memory usage
Create the cache content group
We need a container to store the cached requests, and in the Netscaler world this is called a content group. Let’s create a new one.
After giving it a suitable name, we need to decide on how long we’re going to store the callout responses for. Remember that the Netscaler won’t re-query the live web service if a particular IP address if it’s in the cache, so we don’t want to cache it for too long. I’ve chosen one hour (3600 seconds) in this example, as most visitors won’t spend longer than an hour on a website, although you’d probably use 24 hours as a suitable value for production as it’s unlikely that an IP’s “status” will change more than once per day.
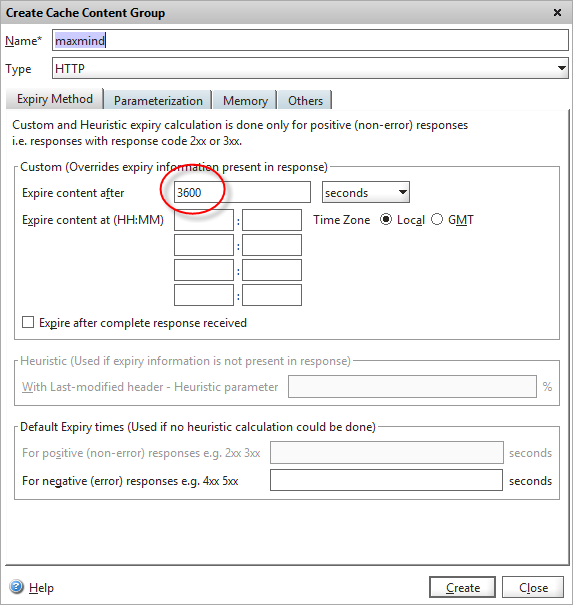
Setting the cache timeout on the new content group
We also need to disable pre-fetch for this content group, so that the Netscaler won’t try to keep the cache valid when entries are close to expiring – we want our call-out to fetch fresh data from the API only if needed by a visitor from the same IP.
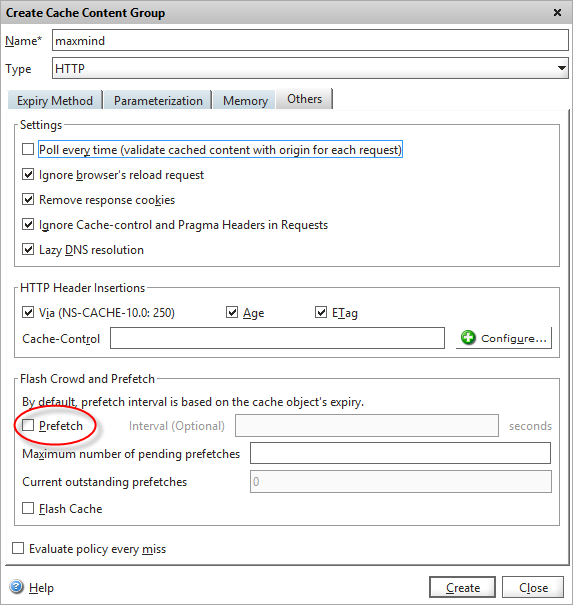
Disable prefetch on the cache content group
We now need to fine-tune our content group with parametrisation. We need to perform this otherwise by default the Netscaler will cache the first API response, and use that for any further calls, regardless of what the users IP address. This would result in value stored in the cache being used to evaluate every visitor to our website, and is obviously detrimental to what we’re trying to achieve.
Defining a cache selector policy
Under the Parameterization tab in our content group, there’s an option to create a “selector policy”. We can define two separate policies here, one that defines cache hits, and one that causes an existing cache entry to be invalidated (i.e. forced expiry). We don’t need the latter in our case, as we’ve configured cache objects to expire automatically after an hour, so we just need to define how the Netscaler selects objects to store. Click on “New..” hit selector.
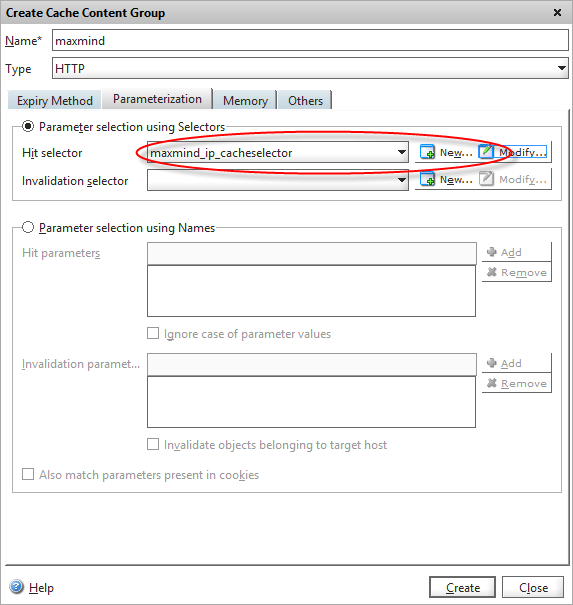
Configure our content group to use a cache selector
We now have a new dialog where we tell the Netscaler how to identify unique cache objects.
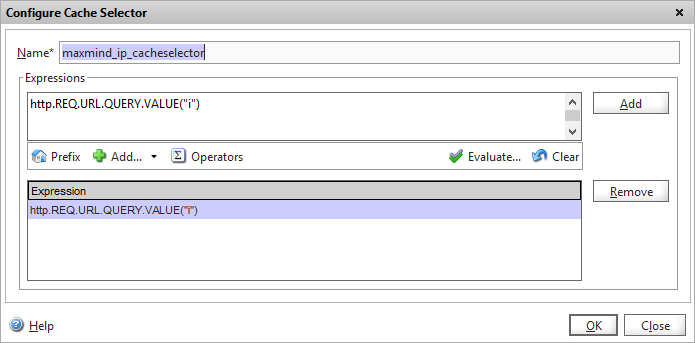
Configuring the cache selector
We want to the Netscaler to cache each unique response to a visitor IP address, so that future callout requests for that client come from the cache and are not passed to Maxmind API. The parameter that defines each unique IP address in our HTTP callout request is “i” so we build an expression that matches this:
HTTP.REQ.URL.QUERY.VALUE("i")
Click OK and you can then configure the cache content group to use this selector
Binding the cache policy
We now have a policy content group object configured to store our http callout responses in the way we need them. We now need to bind this via a caching policy to the service that the HTTP callout traffic is made from, and determine when it’s called. Under integrated cache, let’s create a new Cache policy.
Give it a sensible name, change the action to “CACHE” and tell the policy to store the contents in the caching group we created earlier.
We now define an expression that will trigger the item to be placed into the cache. In this case, I’m just querying the host header that we defined in our HTTP callout object a while back (seems like a long time ago now!) so if the traffic is destined for the API, it needs to be cached.
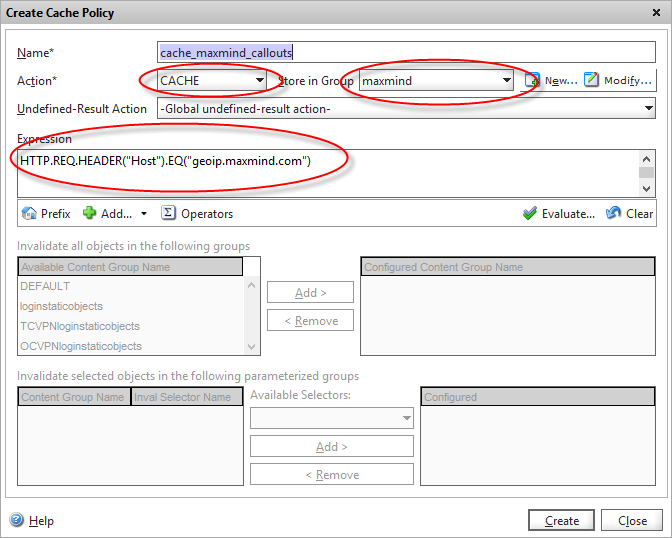
Creating a cache policy to define when content is stored in our new content group
We then bind this using the policy manager to the load-balanced virtual server we created for the Maxmind API.
And we’re done! We now have a real-time GeoIP query via caching HTTP call-out!
Testing
We need to test that everything is working as expected. The first place to check whether our call-out is being activated is the hit counter on the call-out object itself.
Check the hit counter to ensure our callout is being activated
This should start to increase rapidly as traffic hits the main website and call-outs are being made to query the clients IP addresses.
How do we know if our cache is working? Let’s look into the cache content group. Select the “cache objects” and then choose our new content group from the drop-down, and click “Go” – this will show just objects from our new call-out cache.
We should see one cache object per-client IP as per below.
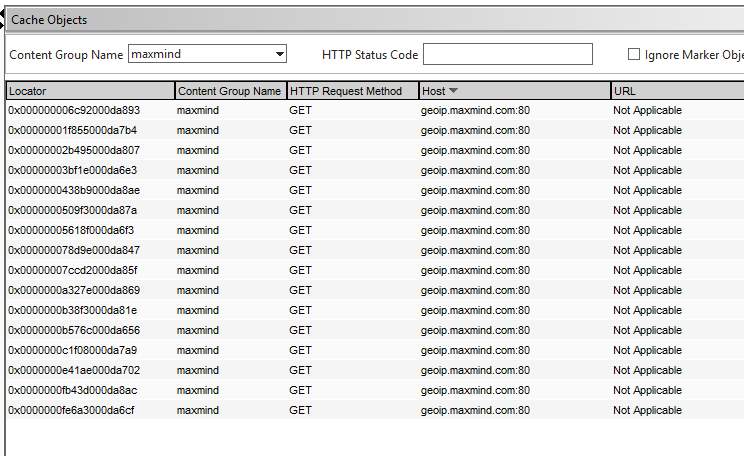
Cache objects after enabling for a while
Examining each of these should show a unique response to the API query. There are some tips on how to further analyse cached HTTP callout requests here.
It’s easier to examine one of our cache objects from the command line:
> show cache object -locator 0x0000000b576c000da656 Integrated cache object statistics: Response size: 10 bytes Response header size: 0 bytes Response status code: 200 ETag: NONE Last-Modified: NONE Cache-control: max-age=0 ,private Date: Thu, 28 Mar 2013 13:09:11 GMT Contentgroup: maxmind Complex match: YES Host: geoip.maxmind.com Host port: 80 Hit selector: maxmind_ip_cacheselector Values of selector expressions: 1) http.REQ.URL.QUERY.VALUE("i"): 94.173.215.234 < This is the IP address passed to the callout Destination IP: 0.0.0.0 Destination port: 0 Request time: 14376 secs ago Response time: started arriving 14376 secs ago Age: 14382 secs Expiry: Already expired Flushed: NO Prefetch: disabled Current readers: 0 Current misses: 0 Hits: 48 < We can see that we've had lots of hits, so our cache is being utilised Misses: 1 < We'll always get 1 miss, as the first call is never in the cache so always a miss Compression Format: NONE HTTP version in response: 1.0 Weak ETag present in response: NO Negative marker cell: NO Auto poll every time: NO NetScaler ETag inserted in response: NO Full response present in cache: YES Destination IP verified by DNS: NO Stored through a cache forward proxy: NO Delta basefile: NO Waiting for minhits: NO Minhit count: 0 App Firewall MetaData Exists: NO HTTP request method: GET Stored by policy: NONE HTTP callout cell: YES < Shows us that this object comes from a HTTP callout request HTTP callout name: callout_Maxmind < The name of the callout object HTTP callout type: TEXT < The type of callout object HTTP callout response: GB < The resulting data that's stored in the cache Done
We should also check that our API quota isn’t being gobbled up at a ferocious rate. Here is my API query quota remaining when I enabled the call-out policy:
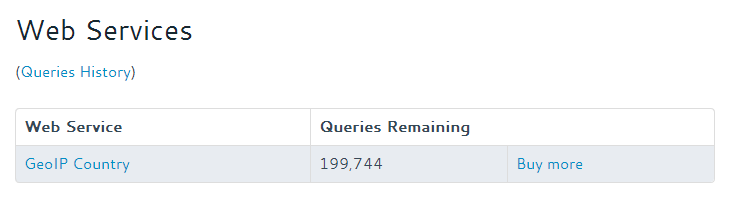
Maxmind callout queries before enabling the callout
And a few minutes later when there had been several visitors to the website:
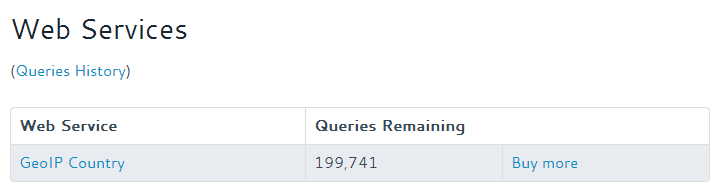
Maxmind quota after enabling the callout for a period
As you can see our quota has only gone down by 3, but our call-out policy has been called hundreds of times in this duration:
Lots of callouts being made, but they aren’t reaching Maxmind! Result!
So our cache has soaked up hundreds of callout requests for the same IP address, speeding up the page and saving us many hundreds of API queries that we pay for.
A bonus callout
OK, earlier we looked at detecting search engine crawlers by defining a pattern set and then comparing the user-agent header with its contents. As this blog post is mostly about HTTP callouts, I thought I’d throw in a bonus callout that actually queries an API to discover if the user-agent is a known search engine or crawler.
You wouldn’t want to do this for real – the overhead of performing this against each HTTP request would kill performance. This is only for fun folks!
So, I’ve followed the same process as for the Maxmind callout, and now need to customise the callout request to pass the correct data to the API.
Method is still GET, host expression remains the hostname of the target web service. There is no STEM required, as the API accepts it query string against the root.
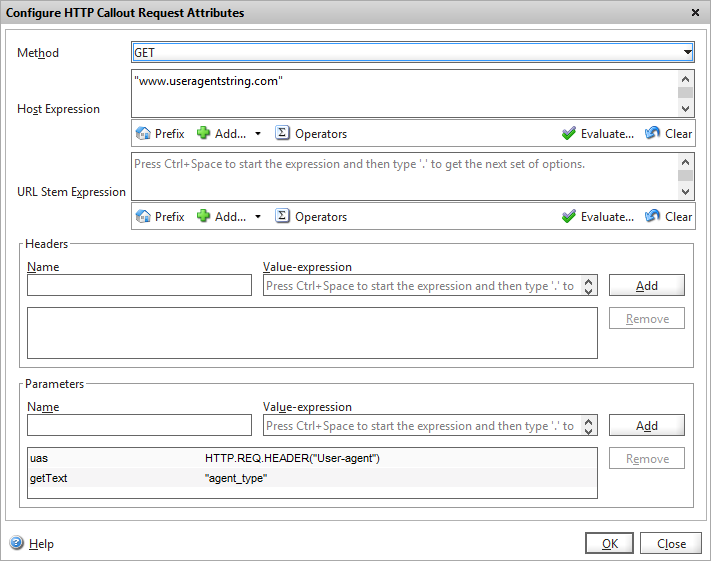
Adding a callout to query the user agent type
We have two Parameters to pass in: “uas” which is the actual full user-agent header as sent by the end user. This can be extracted from the incoming request using the expression
HTTP.REQ.HEADER(“User-agent”)
The second parameter is to tell the API we’re only interested in receiving the agent_type back, rather than all the other data that’s available to us. If some of the data would be of interest to is, we could easily omit this parameter and then extract the data we’re interested in using an expression in the callout server response object.
You’d then configure equivalent caching policies as the Maxmind callout which I’m not going to detail again.
I hope you’ve found this useful and informative – please leave a comment below if so!
Command reference
Here are all the ns commands used in this article for your reference.
add policy patset web_crawler_user_agents
bind policy patset web_crawler_user_agents googlebot
bind policy patset web_crawler_user_agents "Yahoo! Slurp"
bind policy patset web_crawler_user_agents msnbot
add policy httpCallout callout_Maxmind
set policy httpCallout callout_Maxmind -vServer vs_maxmind -returnType TEXT -hostExpr "\"geoip.maxmind.com\"" -urlStemExpr "\"/a\"" -parameters l("API_key_here") i(Client.IP.SRC) -resultExpr "HTTP.RES.BODY(3)"
add locationFile "/var/netscaler/locdb/GeoIPCountryWhois.csv" -format geoip-country
add server geoip.maxmind.com geoip.maxmind.com
add service svc_maxmind_80 geoip.maxmind.com HTTP 80 -gslb NONE -maxClient 0 -maxReq 0 -cip DISABLED -usip NO -useproxyport YES -sp ON -cltTimeout 180 -svrTimeout 360 -CustomServerID "\"None\"" -CKA YES -TCPB NO -CMP YES
add lb vserver vs_maxmind HTTP 0.0.0.0 0 -persistenceType NONE -cltTimeout 180
set cache parameter -memLimit 512 -via "NS-CACHE-10.0: 250"
add responder action display_blocked_page respondwith "\"<html><body>Sorry, the IP address you are connecting from (\"+CLIENT.IP.SRC+\") is categorised as anonymous proxy so you are unable to access our systems</body></html>\""
add responder policy pol_block_anon_proxies_realtime "HTTP.REQ.HEADER(\"user-agent\").SET_TEXT_MODE(IGNORECASE).CONTAINS_ANY(\"web_crawler_user_agents\").NOT&& SYS.HTTP_CALLOUT(callout_Maxmind).contains(\"A1\")" display_blocked_page
add responder policy pol_block_anon_proxies_static "HTTP.REQ.HEADER(\"user-agent\").SET_TEXT_MODE(IGNORECASE).CONTAINS_ANY(\"web_crawler_user_agents\").NOT&&CLIENT.IP.SRC.MATCHES_LOCATION(\"*.A1.*.*.*.*\")" display_blocked_page
set responder param -undefAction NOOP
add cache selector maxmind_ip_cacheselector "http.REQ.URL.QUERY.VALUE(\"i\")"
add cache contentGroup maxmind -relExpiry 3600 -prefetch NO -hitSelector maxmind_ip_cacheselector
add cache policy cache_maxmind_callouts -rule "HTTP.REQ.HEADER(\"Host\").EQ(\"geoip.maxmind.com\")" -action CACHE -storeInGroup maxmind
bind lb vserver vs_maxmind svc_maxmind_80
bind lb vserver vs_maxmind -policyName cache_maxmind_callouts -priority 100 -gotoPriorityExpression END -type REQUEST
Leave a comment
You must be logged in to post a comment.

3 Comments
Leave a commentTrackbacks and Pingbacks